Modern software now behaves less like a single application and more like a living ecosystem. Services are spread across Kubernetes clusters, multiple clouds, data platforms, queues, and third‑party APIs, all changing several times a day. When a user says, “The app is slow,” the root cause might sit in an overloaded microservice, a noisy neighbor in the cluster, a malformed query, or a hidden network problem.
In this reality, traditional monitoring is not enough. Teams need a way to understand systems from the outside—by looking at what they emit in real time. That is the job of Observability Engineering. It is about shaping telemetry (metrics, logs, traces, events, profiles) so that you can answer tough questions about system health quickly and confidently.
This guide is written for working engineers and managers—whether you build products in India or lead platforms in a global enterprise. Drawing on two decades of experience across DevOps, SRE, and large‑scale systems, I will walk you through what observability really means, why it matters now, and how the Master in Observability Engineering certification can act as a structured path to become an observability specialist.
Observability Engineering in Plain Language
At its core, observability answers one simple question: “Can I look at the external outputs of my system and confidently explain what is going on inside?”
An Observability Engineer focuses on:
- Designing the right signals from services and infrastructure.
- Ensuring data can be collected, stored, and queried efficiently.
- Turning that data into insight that helps people take action.
When this is done well, you can spot problems early, compare how the system behaves today versus last week, and understand why outages or performance issues are happening instead of guessing.
Why Observability Has Become Critical
There are a few big shifts that push observability to the front of the stage.
- Architectures are distributed: microservices, containers, service mesh, event‑driven systems.
- Releases are frequent: CI/CD pipelines push changes many times a day.
- Users are global: small issues in one region can quickly become business‑critical.
- SLAs, SLOs, and compliance: reliability is now a measurable contractual obligation.
Without strong observability, incidents last longer, war rooms become chaotic, and teams fall back to “try this and see” behavior. With mature observability, you reduce MTTD and MTTR, ship faster with confidence, and build a shared language between developers, SREs, security, data, and business stakeholders.
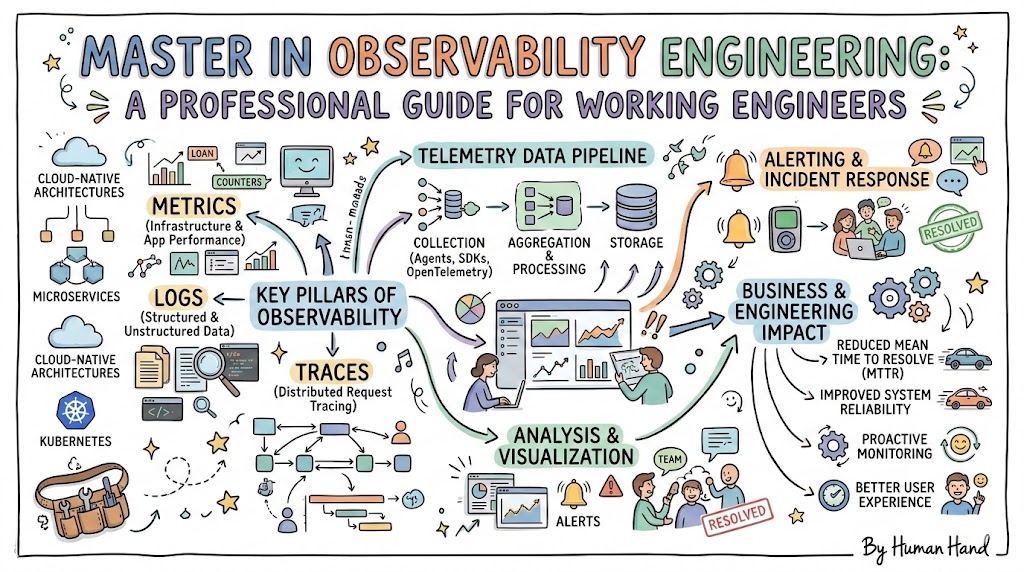
The Building Blocks: Metrics, Logs, Traces, and Beyond
Metrics
Metrics are numeric values captured over time: latency, error rate, CPU, memory, RPS, queue depth, and so on. They are ideal for dashboards and alerts because they are compact and easy to aggregate. Tools like Prometheus and time‑series databases are common here.
Logs
Logs are structured or semi‑structured records of what happened: errors, warnings, business events, and audit records. They are powerful for deep investigations, especially when you design them with consistent formats and correlation IDs. Centralized log platforms (ELK/EFK, similar stacks) are standard in observability setups.
Traces
Traces show the end‑to‑end journey of a request across services, queues, and databases. In microservices and serverless systems, tracing is often the only practical way to see where latency and failures are introduced. Distributed tracing and context propagation are key skills for an Observability Engineer.
Events, Profiles, and More
- Events capture significant changes like deployments, config changes, feature flag flips.
- Profiles highlight how code uses CPU and memory over time.
A strong observability approach combines all these signals, so you can move from “something is wrong” to “this specific change in this component caused this failure” in minutes, not hours.
Certification Snapshot – Master in Observability Engineering
What it is
MOE is an advanced, industry‑oriented certification that trains you to design, implement, and operate observability for complex systems across on‑premise, cloud, and hybrid environments. It goes beyond basic monitoring and teaches you how to create meaningful telemetry, connect it to SRE practices, and use it for incident response, performance tuning, and business decisions.
Who should take it
- DevOps, SRE, and Platform Engineers responsible for production systems.
- Cloud and Infrastructure Engineers owning SLAs and reliability.
- Backend / full‑stack developers moving into SRE or platform roles.
- Security and Data engineers who depend on reliable telemetry.
- Engineering Managers defining observability standards for their teams.
Skills you’ll gain
- Observability principles and architecture for different system types.
- Instrumentation using OpenTelemetry SDKs, agents, and collectors.
- Metrics, logs, traces, and events: design, collection, storage, and querying.
- Working with tools like Prometheus, Grafana, log platforms, and cloud metrics services.
- Building effective dashboards, alerts, and SLO/SLI frameworks.
- Running incident response with observability data and post‑incident analysis.
- Applying analytics and automation (including AI‑driven insights) on top of telemetry.
Real‑world projects you should handle after MOE
- Implement a full observability stack for a Kubernetes‑based application, including metrics, logs, traces, dashboards, and alerting.
- Retrofit a legacy “monitoring‑only” system with modern observability capabilities using OpenTelemetry.
- Design SLOs/SLIs for a critical user journey and build alerting around error budgets.
- Integrate observability with CI/CD to validate deployments, canaries, and rollbacks.
- Lead a post‑incident review where observability data is used to find root cause and prevention steps.
Preparation plan (7–14 days / 30 days / 60 days)
7–14 days (fast‑track for experienced professionals)
- Days 1–3: Refresh core ideas—observability vs monitoring, pillars, common tools, and OpenTelemetry basics.
- Days 4–7: Build or update a lab with Prometheus, Grafana, and logs for a demo app; practice basic tracing.
- Days 8–11: Focus on SLOs, SLIs, alerting strategies, and incident workflows.
- Days 12–14: Do a compact project and revise the main topics from the course outline.
30‑day balanced plan
- Week 1: Fundamentals—pillars of observability, architecture patterns, key tools.
- Week 2: Tool mastery—Prometheus, Grafana, log stack, and cloud monitoring features.
- Week 3: Distributed tracing, OpenTelemetry collectors, microservices, and service mesh scenarios.
- Week 4: Advanced items like anomaly detection plus an end‑to‑end project with documentation and demo.
60‑day deep mastery plan
- Weeks 1–2: Foundational skills in Linux, networking, containers, Kubernetes, plus basic monitoring.
- Weeks 3–4: Multiple toolchains, multi‑environment setups, and automation of dashboards/alerts.
- Weeks 5–6: Complex topologies—multi‑cluster, multi‑account, mixed on‑prem and cloud, plus AI‑driven insights and optimization.
- Final: One capstone that mirrors a real production landscape.
Common mistakes learners make
- Treating observability as a “tool install” instead of a design problem.
- Collecting large amounts of logs without structure or strategy, driving cost up and value down.
- Underusing traces, especially in microservices, and relying only on dashboards.
- Creating alert rules that are noisy and not tied to user impact or SLOs.
- Ignoring the connection between observability and DevOps/SRE processes, like on‑call runbooks and incident reviews.
Best next certification after MOE
From DevOpsSchool’s broader ecosystem, especially the Master in DevOps Engineering track, these make strong follow‑ups:
- Same technical depth: Master in DevOps Engineering (MDE) for full DevOps architecture and automation.
- Reliability focus: SRE‑oriented certifications to strengthen reliability engineering.
- Security angle: DevSecOps‑focused credentials where you apply observability to security events and controls.
MOE Certification Table
| Track | Certification | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|---|
| Observability / SRE | Master in Observability Engineering (MOE) | Advanced | DevOps, SRE, Platform, Cloud, Backend Engineers; Engineering Managers responsible for system health | Basic Linux and networking, one programming/scripting language, exposure to DevOps or cloud platforms, and some monitoring experience | Observability foundations; metrics, logs, traces; OpenTelemetry; Prometheus, Grafana, log stacks, cloud monitoring; SLO/SLI and alerting; incident response; cloud‑native and Kubernetes observability; analytics and automation | Best taken after gaining DevOps/cloud basics or completing a foundation‑level program and 1–2 years of practical experience |
Choose Your Path – 6 Practical Learning Routes
Observability sits at the center of many modern disciplines. Here is how MOE fits into six major paths, using DevOpsSchool’s ecosystem (including Master in DevOps Engineering) as context.
1 DevOps Path
- Step 1: Learn DevOps fundamentals—Git, CI/CD, containers, configuration management.
- Step 2: Pursue DevOps certifications such as MDE to cover end‑to‑end delivery and platform design.
- Step 3: Add MOE to make your pipelines and platforms visible, measurable, and easier to operate.
- Step 4: Grow into roles like DevOps Architect or Platform Engineer.
2 DevSecOps Path
- Start from DevOps, then learn security tooling, secure SDLC, and threat modeling.
- Add a DevSecOps‑oriented certification to cement the security mindset.
- Use MOE to build telemetry pipelines for security events, anomalies, and policy violations.
- Progress toward roles like DevSecOps Engineer or Security Operations Architect.
3 SRE Path
- Learn SRE principles—SLIs, SLOs, error budgets, capacity planning, and on‑call practices.
- Take SRE‑specific training and certifications.
- Use MOE to gain the observability depth you need to implement those SRE concepts in real systems.
- Evolve into Senior/Lead SRE roles where you design reliability strategies.
4 AIOps / MLOps Path
- Build DevOps and data/ML basics first.
- Add MLOps or AIOps certifications to understand models, pipelines, and ML‑powered operations.
- Use MOE to create the telemetry foundation feeding AIOps engines and ML‑based anomaly detection.
- Move towards roles blending data, ML, and operations, like AIOps Engineer.
5 DataOps Path
- Start with data engineering skills—pipelines, ETL/ELT, warehousing.
- Take DataOps‑focused training that emphasizes reliability and governance.
- Use MOE to observe data flows, job performance, quality metrics, and platform health.
- Grow into Data Reliability, Data SRE, or Platform roles in analytics environments.
6 FinOps Path
- Begin with cloud cost and financial operations fundamentals.
- Add FinOps training and practitioner certifications.
- Use MOE to supply accurate usage, performance, and capacity metrics that FinOps decisions depend on.
- Advance to roles focused on cost‑aware architecture and multi‑cloud governance.
Role → Recommended Certifications Mapping
Here is a concise mapping between common roles and how MOE plus related certifications fit into their journey, based on DevOpsSchool’s MDE ecosystem and observability content.
| Role | Primary focus | Start with | When to add MOE | After MOE, focus on |
|---|---|---|---|---|
| DevOps Engineer | CI/CD, infra automation | DevOps basics, DevOps Certified Professional, then MDE | Once pipelines and environments are stable in production | SRE certifications, Kubernetes specializations, GitOps‑focused tracks |
| Site Reliability Engineer (SRE) | Reliability and SLOs | SRE principles and SRE‑oriented training | Early to mid‑career, when you need deeper telemetry to support SLOs | Advanced SRE, chaos and resilience engineering |
| Platform Engineer | Internal platforms and Kubernetes | MDE, Kubernetes admin/developer training | When you manage shared platforms with many teams onboarded | AIOps, large‑scale platform design, GitOps at scale |
| Cloud Engineer | Cloud infra and services | Cloud provider certs plus DevOps fundamentals | As soon as you start owning production workloads and SLAs | FinOps, security, multi‑cloud SRE and reliability tracks |
| Security Engineer | Detection and response | Security and DevSecOps programs | When you need rich security telemetry and threat visibility | Advanced DevSecOps, security analytics, SOAR‑style operations |
| Data Engineer | Data pipelines and platforms | Data engineering and DataOps training | When data pipelines are business‑critical and must be observable | Data SRE, AIOps/MLOps, performance and cost optimization for data infra |
| FinOps Practitioner | Cost optimization and governance | FinOps training and practitioner credentials | When cost, usage, and performance data need to be aligned | Advanced FinOps, executive reporting, policy‑driven governance |
| Engineering Manager | Delivery and reliability leadership | DevOps/SRE leadership training, MDE | When defining team/organizational observability standards | Architecture, platform strategy, and high‑level reliability governance |
Top Institutions Supporting Master in Observability Engineering
Several institutions within the same ecosystem help professionals train for observability and related certifications. They typically combine live training, self‑paced content, labs, doubt‑clearing sessions, and post‑course support.
- DevOpsSchool – A flagship platform offering DevOps, SRE, observability, DataOps, AIOps, MLOps, DevSecOps and more, including the Master in Observability Engineering program. It focuses on practical labs, real‑world scenarios, and certification‑ready skills for working professionals.
- Cotocus – A consulting and training company that works with enterprises to implement DevOps and SRE transformations. They often use observability‑centric approaches and rely on structured courses for team enablement.
- ScmGalaxy – Known for DevOps, configuration management, CI/CD, and tooling education. Their offerings complement observability by strengthening your automation and release skills.
- BestDevOps – A content‑driven community hub and knowledge portal for DevOps, SRE, and observability learners. It aggregates guidance, blogs, and learning paths aligned with the DevOpsSchool ecosystem.
- DevSecOpsSchool – Focused on integrating security into DevOps practices, where logs, metrics, and events from observability setups are crucial for security detection and response.
- SRESchool – Dedicated to SRE principles, SLO design, and reliability operations. It aligns naturally with MOE for professionals targeting SRE roles.
- Aiopsschool, Dataopsschool, Finopsschool – These specialize in AIOps, DataOps, and FinOps respectively, where observability data is used for intelligent automation, data reliability, and cost optimization. Combining their programs with MOE can create a strong cross‑disciplinary profile.
Next Certifications to Take After MOE (Same Track, Cross‑Track, Leadership)
Using DevOpsSchool’s Master in DevOps Engineering (MDE) ecosystem as reference, here are three clear directions once you complete MOE.
1 Same track – Deepen DevOps/SRE depth
- Target: Broader ownership of the full delivery and operations pipeline.
- Recommended: Master in DevOps Engineering (MDE) to cover CI/CD, IaC, automation, and multi‑tool ecosystems end‑to‑end.
2 Cross‑track – Security (DevSecOps)
- Target: Use observability to strengthen security.
- Recommended: DevSecOps‑oriented certifications where you learn how telemetry supports security monitoring, policy enforcement, and incident response.
3 Leadership – Architecture and Strategy
- Target: Tech lead, architect, or manager role.
- Recommended: SRE/DevOps leadership and architecture‑focused programs that build on MOE and MDE to help you define standards, patterns, and governance across multiple teams.
General FAQs – Difficulty, Time, Value, Career Outcomes
1. Is Observability Engineering a niche skill or a mainstream requirement?
It is moving rapidly from niche to mainstream, especially in organizations running cloud‑native, distributed, or high‑scale systems. Companies now expect teams to design and use observability as part of how they build and operate software.
2. How hard is the Master in Observability Engineering for a working engineer?
If you already know Linux, basic networking, and some DevOps or monitoring tools, you will find MOE challenging but very manageable. The main learning curve is thinking in terms of signals, not just tools.
3. How much time should I realistically plan for preparation?
Most people can prepare well in 30–60 days by combining course sessions, labs, and a small project. Experienced SRE/DevOps professionals can fast‑track in about two weeks with focused effort.
4. Do I need a specific tech stack background (Java, Node, etc.)?
No single stack is mandatory, but you should be comfortable reading and instrumenting code in at least one language used in your environment. Observability concepts apply across languages and frameworks.
5. Is it better to do a DevOps certification before MOE?
For many people, yes. A DevOps‑focused certification like MDE or similar foundations helps you understand CI/CD, infrastructure, and operational contexts, which makes observability patterns easier to apply.
6. Does MOE add real value to my career, or is it just another badge?
MOE is valuable when paired with real projects. It signals that you understand how to turn telemetry into practical outcomes—faster incident resolution, better reliability, and improved user experience. Employers increasingly look for these capabilities in senior DevOps/SRE roles.
7. Where does MOE sit in a typical learning sequence?
A common sequence is: DevOps/cloud basics → some real experience → MDE or equivalent → MOE → SRE/DevSecOps/DataOps/FinOps specialization. You can adjust the order depending on your current role.
8. What kind of salary or role uplift can I expect?
While exact numbers depend on region and company, engineers who own observability, SRE, and platform responsibilities typically progress faster into senior, lead, or architect positions, which come with higher compensation.
9. Does observability help non‑production teams like development or data teams?
Yes. Developers use observability to catch performance regressions early, and data teams rely on telemetry to monitor data quality, job health, and pipeline performance.
10. Will automation or AIOps replace Observability Engineers?
AIOps tools rely on observability data to work. Someone still needs to design telemetry, define what “normal” looks like, and ensure the right signals exist. In practice, observability engineers often drive effective AIOps adoption.
11. Is MOE relevant if my company is still monolithic and on‑prem?
Yes. Monoliths also benefit from clear metrics, logs, and traces. As your architecture evolves, having observability in place makes migration to microservices or cloud smoother and safer.
12. Can Engineering Managers benefit, or is this only for hands‑on engineers?
Managers who understand observability can set better SLAs, design more effective on‑call processes, and have data‑driven conversations about reliability and investment. It is highly relevant for leadership roles.
MOE‑Specific FAQs
1. What exactly does the MOE curriculum cover?
It spans observability fundamentals, OpenTelemetry, metrics/logs/traces, key tools (Prometheus, Grafana, log platforms, cloud monitoring), cloud‑native and Kubernetes observability, alerting, incident response, and advanced analytics.
2. Is the course more tool‑centric or concept‑centric?
It balances both. You learn concepts first and then apply them through tools and labs, which is important because tools change but principles remain.
3. What level of experience do trainers usually have?
DevOpsSchool’s ecosystem highlights trainers with many years of industry experience in DevOps, SRE, and related domains, bringing real project scenarios into the classroom.
4. How is learning delivered?
MOE is available in instructor‑led online sessions, self‑paced content, and corporate batches, with labs, assignments, and project‑based assessments.
5. Is there a project requirement?
Yes, you work on practical assignments and at least one real‑style project that requires implementing observability end‑to‑end, similar to MDE’s capstone style.
6. Can fresh graduates take MOE directly?
They can, but it is demanding. Freshers are usually better served by building DevOps/cloud fundamentals first before targeting a “Master”‑level observability program.
7. Is the MOE certificate time‑bound?
DevOpsSchool certifications are designed as long‑term credentials once you successfully complete training and evaluation, with emphasis on practical capability rather than periodic renewal.
8. How does MOE compare with a generic monitoring course?
Generic monitoring courses often stop at tools and dashboards. MOE focuses on observability as a discipline—covering design, distributed tracing, OpenTelemetry, SLO‑driven thinking, and real incident handling, which is far broader and deeper.
Conclusion
Observability Engineering has become one of the most strategic skills in modern IT. It transforms scattered signals into a clear picture of how systems behave, why they fail, and how they can be improved. The Master in Observability Engineering (MOE) certification by DevOpsSchool offers a structured, hands‑on way to build these capabilities and prove them to employers.Whether you are a DevOps Engineer, SRE, Platform Engineer, Security Engineer, Data Engineer, FinOps Practitioner, or Engineering Manager, investing in observability will raise your impact, your confidence, and your long‑term career value. MOE can be the anchor certification that turns you from “someone who uses monitoring tools” into the person the organization trusts to keep complex systems visible, reliable, and continuously improving.